Abstract
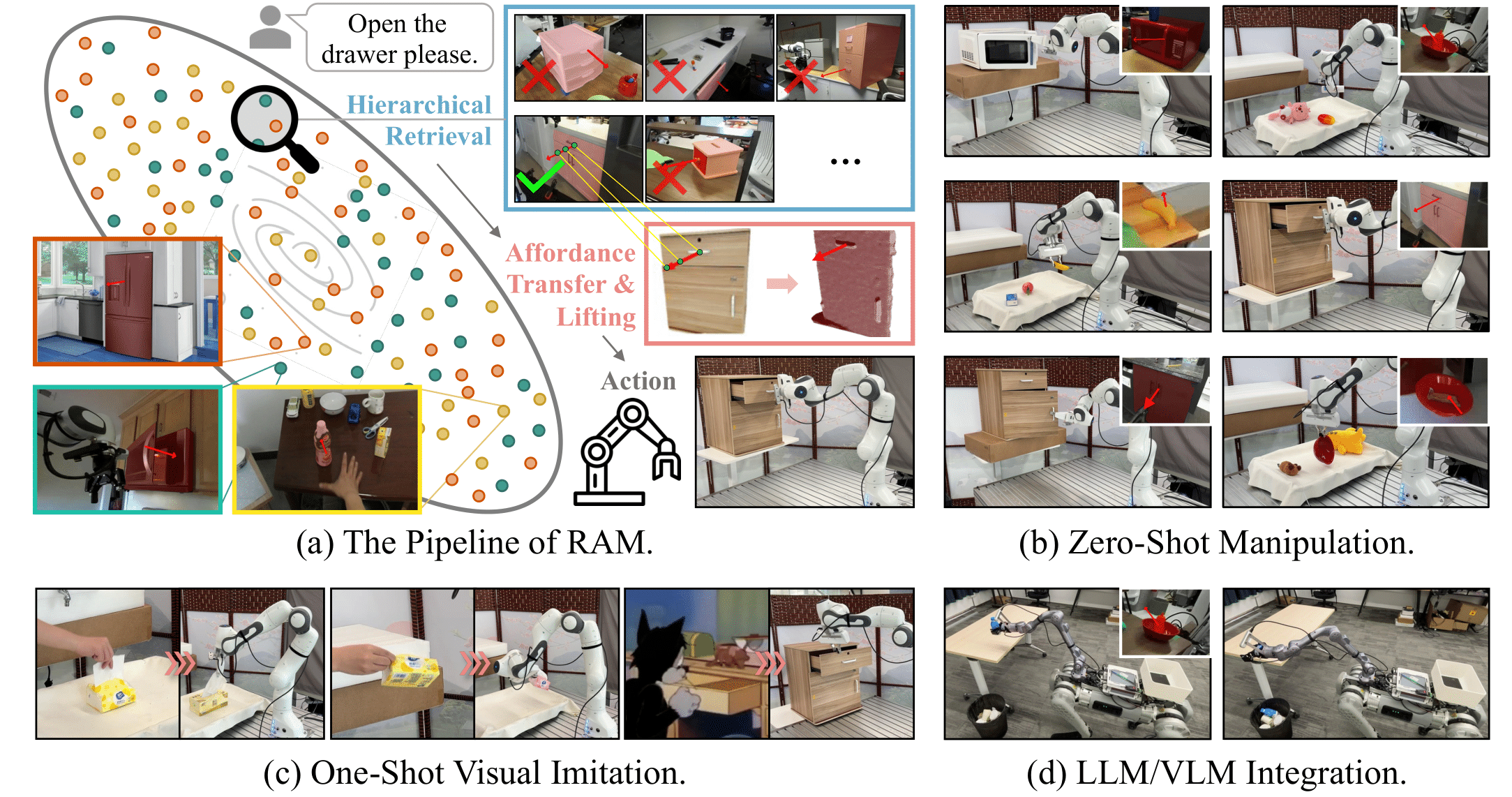
This work proposes a retrieve-and-transfer framework for zero-shot robotic manipulation, dubbed RAM, featuring generalizability across various objects, environments, and embodiments. Unlike existing approaches that learn manipulation from expensive in-domain demonstrations, RAM capitalizes on a retrieval-based affordance transfer paradigm to acquire versatile manipulation capabilities from abundant out-of-domain data. First, RAM extracts unified affordance at scale from diverse sources of demonstrations including robotic data, human-object interaction (HOI) data, and custom data to construct a comprehensive affordance memory. Then given a language instruction, RAM hierarchically retrieves the most similar demonstration from the affordance memory and transfers such out-of-domain 2D affordance to in-domain 3D executable affordance in a zero-shot and embodiment-agnostic manner. Extensive simulation and real-world evaluations demonstrate that our RAM consistently outperforms existing works in diverse daily tasks. Additionally, RAM shows significant potential for downstream applications such as automatic and efficient data collection, one-shot visual imitation, and LLM/VLM-integrated long-horizon manipulation.
Video
Real-Robot Rollouts
Zero-Shot Robotic Manipulation (2x)
NOTE: All rollouts are fully autonomous, WITHOUT any heuristic grasping.
One-Shot Visual Imitation with Human Preference (2x)
(Recommend Chrome for better compatibility)
(Recommend Chrome for better compatibility)
LLM/VLM Integration (3x)
BibTeX
@article{kuang2024ram,
title={RAM: Retrieval-Based Affordance Transfer for Generalizable Zero-Shot Robotic Manipulation},
author={Kuang, Yuxuan and Ye, Junjie and Geng, Haoran and Mao, Jiageng and Deng, Congyue and Guibas, Leonidas and Wang, He and Wang, Yue},
journal={arXiv preprint arXiv:2407.04689},
year={2024}
}